type
status
date
slug
summary
tags
category
icon
password

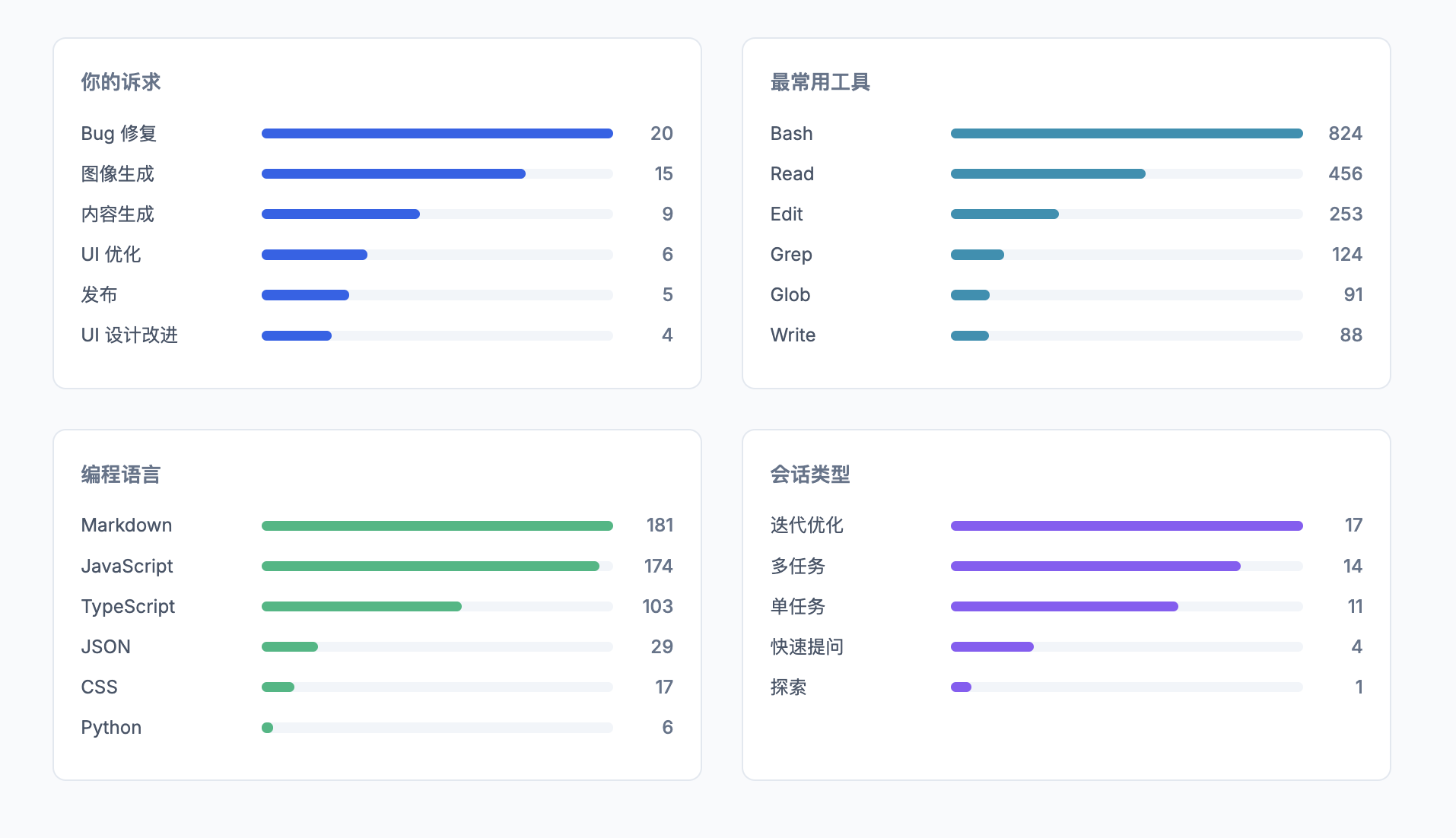
我有一个习惯:凡是长期使用的工具,我会找机会把使用记录翻出来看一遍。
不是为了批判,是为了校准。因为主观感受会漂移,但数据不会。
最近我把用 Claude Code 过去一个月时间积累的会话数据整理了一遍。两个目录:
session-meta 存量化指标(时长、token 消耗、改了多少行代码);facets 存每次会话的质量分析(目标是否达成、Claude 有没有帮上忙、卡在哪里了)。通过调用 /insight 命令,我让 Claude Code 给出一份专业报告。

第一个意外:用户的消息数量少得惊人
我原以为 AI 编程是双向的——你说一点,它做一点,来来回回。
但数据说的是另一个故事。
一次给 SpeechNote 加 AI 优化历史记录功能的会话:用户消息 8 条,助手消息 112 条,用了 Read、Edit、Grep、Bash 等工具合计六七十次,最终写入了 860 行新代码,删除 7 行,修改了 6 个文件。功能包括本地持久化存储、UI 展示层、Supabase 云端同步、数据库 migration SQL 脚本。
8 条消息,一个完整功能。
另一次做 App Store 上架前的全面 review——安全漏洞扫描、免费用户层优化、核心 bug 修复、文档更新——9 条用户消息,助手 156 条响应,调用了 26 次 Edit 操作、14 次 Grep。
这不是"人机协作",更接近"人给需求,机器执行,人验收"。
我说的"消息少"是真的少。很多会话里,用户的输入就是一行编译器错误日志,或者一句"这个 logo 看上去太小了"。然后 Claude 自己去读代码、推理上下文、制定方案、执行、报告结果。

第二个意外:Claude 最有价值的地方,不是它最聪明的地方
facets 数据里有一个字段叫 claude_helpfulness,分五档:essential、very_helpful、moderately_helpful、slightly_helpful、unhelpful。我本来猜测,标记为
essential(不可或缺)的会话,应该是那些需要深度推理的复杂算法、架构设计或者技术攻坚。但实际上,
essential 最密集的地方是两类场景:一是跨文件的功能实现。 加一个功能可能要动 6 个文件,每个文件都有自己的上下文、接口约定、依赖关系。人来做需要不停切换、记忆、比对,极其耗心力。Claude 同时持有整个 codebase 的上下文,做这种"多文件协调"效率远超人工。
二是端到端的流程串联。 比如写一篇文章、生成配图、上传 GitHub 图床、转 HTML、发布到微信公众号——这整条链路可以在一次会话里完成,不需要人在中间每步切换工具。Claude 在这里的角色不是某个环节特别聪明,而是把所有环节无缝串起来了。
也就是说,Claude 最不可替代的能力,不是深度,是广度 × 持续执行。

第三个意外:失败是有规律的
friction_counts 字段记录了每次会话里遇到的摩擦类型。高频出现的有三种:wrong_approach(走错方向):这是最耗时的一种。典型案例是 iOS 启动画面优化那次——Claude 连续两次实现了会导致空白屏的方案,用户不满意,再改,再出问题。分析原因,是 Claude 在没有充分理解 iOS launch screen 生命周期的情况下,凭直觉猜了一个方向,执行得很努力,但方向本身是错的。buggy_code(代码有 bug):这个最常见,但通常不致命。缺少 import、括号不匹配、类型不兼容——这些错误 Claude 自己能修,一两轮迭代就过了。真正麻烦的是改完一个地方出来新问题,形成连锁反应的时候。比如给一个 Manager 加了 @MainActor,结果下游的 OfflineSyncQueue 也跟着报错,Claude 只好回滚。excessive_changes(改动过多):偶尔会发生——你让它改一个地方,它把周边代码也顺手"优化"了。这种情况通常没有恶意,是 Claude 在主动帮忙,但确实增加了 review 成本,有时候还引入了预期外的变化。有一个更特殊的失败模式,我在好几次会话里反复见到:同一个环境问题,被踩了多次。
nvm 和 npx 的冲突。这个问题至少在三次不同的会话里出现,每次 Claude 都在报错后开始排查,但每次的处理结果都不够彻底,下次换个上下文又掉进去了。直到我专门开了一次会话,让 Claude 把解决方案写进 CLAUDE.md,才算从根上堵住。
这件事让我意识到:Claude Code 的记忆是每次会话独立的。踩过的坑不会自动成为经验,除非你主动把它变成文档。

数字背后的一个细节
session-meta 里有个字段叫
user_response_times,记录用户每次回复之间的等待间隔,单位是秒。我随机翻了几条,看到了这样的数字:
1462.704、2779、1741.059——换算下来是 24 分钟、46 分钟、29 分钟。这是用户在等 Claude 的时间。
一次表面上"3 小时"的会话,用户实际在键盘前输入的时间加起来可能不到 20 分钟。其余时间是在等待、观察、验收结果。
这是一种新的工作节奏:人的参与密度降低了,但决策节点没有消失——你仍然要判断 Claude 的方向对不对,结果能不能接受,下一步要往哪走。主动权还在人这边,只是执行权已经大部分转移出去了。

我现在怎么用它
看完这些数据,我对自己的使用方式做了几个调整:
踩到环境类问题,立刻写文档。 不要让同一个坑被踩第二次。nvm 冲突、IP 白名单、WeChat API 不支持 SVG——这类问题解决一次之后,马上让 Claude 把处理方式更新进 CLAUDE.md,下次就直接跳过。
UI 类任务要给更多约束。 让 Claude 做"这个 logo 看上去太小了,帮我优化",它会往各种方向试。但如果你说"用 ScaleEffect 做一个 0.8 到 1.0 的弹出动画,保持纵横比不变",方向就定了,迭代就快了。模糊需求 + 视觉判断,是它最容易走弯路的组合。
功能级任务放心交给它。 如果需求清晰、范围明确,它真的能端到端地完成,不用担心它跑偏。"加一个 AI 历史记录功能,含本地存储和 Supabase 同步"——这种需求交出去,8 条消息之后基本就能拿到可用的实现。
报告里甚至直接给出了针对我个人使用习惯的配置建议——Skills 封装微信发布工作流、Hooks 在每次文件编辑后自动做类型检查。这些不是泛泛而谈,是根据我自己的 47 个会话里出现过的问题具体生成的。

数据这东西,看的时候总有一点冷峻。
它不会说 Claude Code 多牛多神奇,也不会说它多不靠谱。它只是如实记录了:哪些地方顺了,哪些地方卡了,哪些错误反复出现,哪些任务每次都能完成。
我用下来的感受是:这个工具有效,但它的上限取决于你能不能把它的失败模式管起来。踩过的坑留成文档,模糊的需求变成约束,每次会话结束后问一下"这次哪里不顺,下次怎么规避"——这些工夫,比你去研究怎么写更好的 prompt 更值。
工具会进化。但跟工具配合的习惯,需要你自己建。
/insights 真正的价值可能不在于报告本身写了什么,而在于它让你停下来想了一下:我和 AI 的协作方式,到底是高效的,还是在重复踩同一个坑。
2026.03.06 00:07
沪 · 赵巷
Catalog